[ML] 기계학습 및 딥러닝 기초이론과 암 유전체 데이터 딥러닝 적용 실습 1강, 2강
제1강. 생물정보학 동향
- 생물정보학이란?
- 생물학적인 문제를 이해하기 위한 방법이나 프로그램을 개발하는 학제간 분야를 아우르는 학문
- 주요한 연구대상은 DNA, RNA 등의 염기서열
- 최근 오믹스 빅데이터가 출현함에 따라 다양한 기계학습 및 딥러닝을 수행하여 해결하기 위한 시도가 이루어짐
- -omics
- human genome project 이후 하나의 gene에서 genome을 연구하는 수준으로 확장 -> genomics
- omics데이터의 축적이 기계학습 분야로의 발전을 가져옴
제2강. 기계학습 기초개념 및 평가방법
기계학습 기초개념
- 기계학습(Machine learning) : 컴퓨터로 경험을 활용해 시스템을 개선해 나가는 방법론
- 컴퓨터 시스템의 data(=training data)를 통해 model을 만들어내는 learning(=training) algorithm
- 주요개념 : data set, sample, feature, feature value, sample space, 차원수
- Model training은 data를 통해 hypothesis를 세우고 규칙을 찾아내기 위함 -> data-driven hypothesis
- 결과 정보가 필요(=label)
1) 비연속적 값 -> discrete value : classification
* label이 2개일 때 binary classification
2) 연속적 값 -> continuous value : regression
- Testing : Model training 후 해당 model을 활용하여 예측하는 과정
- goal : training model을 새로운 sample에 적용하는 것 -> "generalization(일반화)가 잘 되었다"
항상 training set에서 좋은 성능을 내지 않음
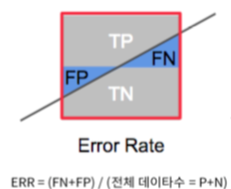
- error : model의 예측 값과 sample의 실제 값 사이의 차이(error rate = a/m, accuracy = 1-a/m)
training set상 만들어낸 오차 = training error
새로운 sample에서 만들어낸 오차 = testing error
* training의 궁극적 목표는 training error가 아닌 testing error를 줄이는 것,
하지만 사전 sample 정보를 얻을 수 없으므로 실제로는 training error를 최소화하는 방법을 찾음
- 새로운 sample data 대상 좋은 성능이란 -> training data에서 모든 data의 보편규칙을 찾아내야 함
하지만, training data에서 학습을 과도하게 잘하면, training data의 특정한 특성을 모든 data에 내재된 일반 성질이라 오해
-> overfitting 즉, generalization 성능이 떨어짐
극복방안) 어려움.. -> 완화, 최소화하도록 연구진행
- training data의 일반성질을 제대로 배우지 못함 -> Underfitting
극복방안) algorithm을 보다 견고하게 만들기
*알고리즘의 발달로 잘 일어나지 않음
기계학습 평가방법
- parameter : algorithm의 parameter(=hyper-parameter) -> 모델 구조 전반에 대한 것 / model의 parameter
- parameter 설정에 따라 model의 성능 차이를 보임 -> model selection시 algorithm의 parameter 설정도 고려해야함
: parameter tuning
- model selection 시 최적의 model을 위해 training set에서 일부를 testing에 사용(testing error를 직접적으로 얻을수 없으므로)
* training set에서의 testing set과 training set의 중복을 최대한 피해야 함
- Validation set : testing set -> 연구에서 혼용하여 사용 잦음
* data set을 적절히 처리하여 traing set, testing set으로 구분
- cross validation : data set을 k개의 disjoint set으로 나누는 것 , k개 testing 가능
일반적으로 10으로 두며 10-fold cross validation(10FCV)라고 함


- Model performance measure : 모델의 generalization 성능 평가 기준 -> performance measure이라고 함
- data의 분석 목적에 따라 결정됨
- 주요개념
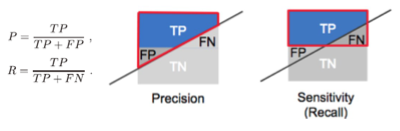
Recall(재현율), Precision(정밀도) -> 분류결과 confusion matrix(혼동행렬)
* 예측한 것 중에 잘 맞추는 것, 실제인 것 중에 잘 맞추는 것 (반비례 관계)
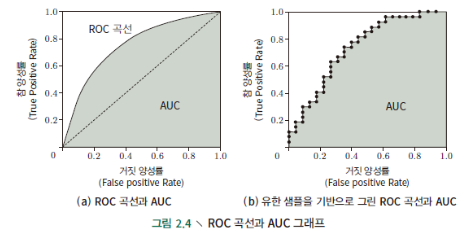
- ROC curve : model 성능을 연구하기 좋은 도구
- test set에 대해 실수값, 확률예측값을 계산하여 예측값과 cut point를 비교
-cut point 보다 크면 positive value, 작으면 negative value
예) 0.5 기준으로 구분
- precision이 중요하다면 큰 값을 cut point, recall이 중요하면 작은 값을 cut point로 설정
- cut point에 따라 각 model의 성능 결정
- 다양한 cut point에 따라 TPR, FPR 값을 계산해서 x,y축에 그린 것
* 대각선은 random prediction model
- 아래 면적을 비교하는 것 -> area under ROC curve(AUC)